Team Building
In-person, virtual, or hybrid adventure to excite your team
- Home
-
Solutions
-

Team Building
In-person, virtual, or hybrid adventure to excite your team -

University & EDU
New student orientation, events, and engagement on campus -

Onboarding & HR
Onboard, activate, and engage new hires and employees -

Conferences & Events
Bring your event to life and engage attendees -

Tourist Destinations
Activate visitors with exciting tours and visitor programs -

Virtual & Remote
Engage and connect remotes anywhere in the world, anytime -

100+ Urban Adventures
100+ Cities with ready-to-go experiences you can start now!
Ready Now
-
- How It Works
- Pricing
- Contact
- Log In
- Get Started
Gamification » Elearning Gamification That Makes Training Stick
eLearning Gamification That Makes Training Stick
Updated: June 11, 2026
If you’ve been handed yet another request to “make the course more engaging,” here’s the blunt version: cosmetics don’t make learning stick. Clear progress, timely feedback, and well-calibrated challenge do. Gamification earns its keep when it strengthens those three, not when it adds confetti to a quiz.
At a Glance
- Anchor gamification to outcomes. Use progress, feedback, and challenge to reduce ambiguity, increase practice, and confirm transfer.
- Design for motivation, not manipulation. Support autonomy, competence, and relatedness to keep participation voluntary and durable.
- Favor retrieval and spacing. Low-stakes practice and scheduled reviews beat one-and-done modules for retention.
- Measure behavior, not vibes. Track attempts, feedback consumption, spaced reviews, on-the-job application.
What “training that sticks” actually means
“Stick” isn’t a feeling; it’s behavior you can observe weeks later. Completion is the starting line, not the finish.
Define “stick” before you design: - Retention: Can learners recall and use the idea after a delay? - Transfer: Do they apply it in realistic scenarios with fewer prompts? - Error reduction: Are common mistakes happening less often? - Time to competence: Are people performing key tasks faster or with less oversight?
Gamification should move at least one of those. If a feature can’t plausibly shift a behavioral metric, it doesn’t belong.
The working model: progress, feedback, and challenge (with purpose)
In our experience, three levers explain most of the lift:
- Progress clarifies path. Visible wayfinding, not just a percentage, reduces cognitive drag and keeps people moving.
- Feedback drives adjustment. Fast, specific, nonjudgmental feedback converts attempts into learning. It also makes practice feel safe.
- Challenge creates stakes. Calibrated difficulty nudges effort and invites retrieval, which is where memory actually forms.
Motivation holds the whole thing together. Environments that support the basic psychological needs of autonomy, competence, and relatedness tend to sustain participation longer than ones that rely on carrot-and-stick tactics. For a concise primer, see this overview of Self‑Determination Theory on the theory’s official site: Self‑Determination Theory: the theory and the basic psychological needs.
What the research really supports (and where it doesn’t)
A pattern we keep seeing in the literature: gamification is helpful when it’s welded to learning mechanics, not when it’s bolted on as decoration.
- Two broad syntheses report positive, often moderate effects on learning outcomes when game elements are aligned to pedagogy and context. See the Educational Psychology Review meta‑analysis on the gamification of learning for nuance by element and setting (Sailer & Homner, 2020) and a more recent Frontiers in Psychology meta‑analysis examining moderators across environments (Frontiers meta‑analysis, 2023).
- Learning improves when learners get timely, specific, and actionable feedback. A widely cited review distills practical patterns for formative feedback that actually helps people change their responses (Shute, 2008).
- Retrieval practice consistently beats re‑reading or watching again for long‑term retention, especially when feedback is built in. See the applied research synthesis across classrooms in Educational Psychology Review (retrieval practice review, 2021).
- Spacing matters. Training that returns to key knowledge after delays tends to hold better than one‑and‑done marathons. The classic meta‑analysis on distributed practice summarizes why (Cepeda et al., 2006).
Where it often doesn’t help: points or badges that reward seat time, leaderboards that publicly shame novices, and streaks that punish breaks rather than encourage healthy spacing. Those patterns can move logins without moving learning.
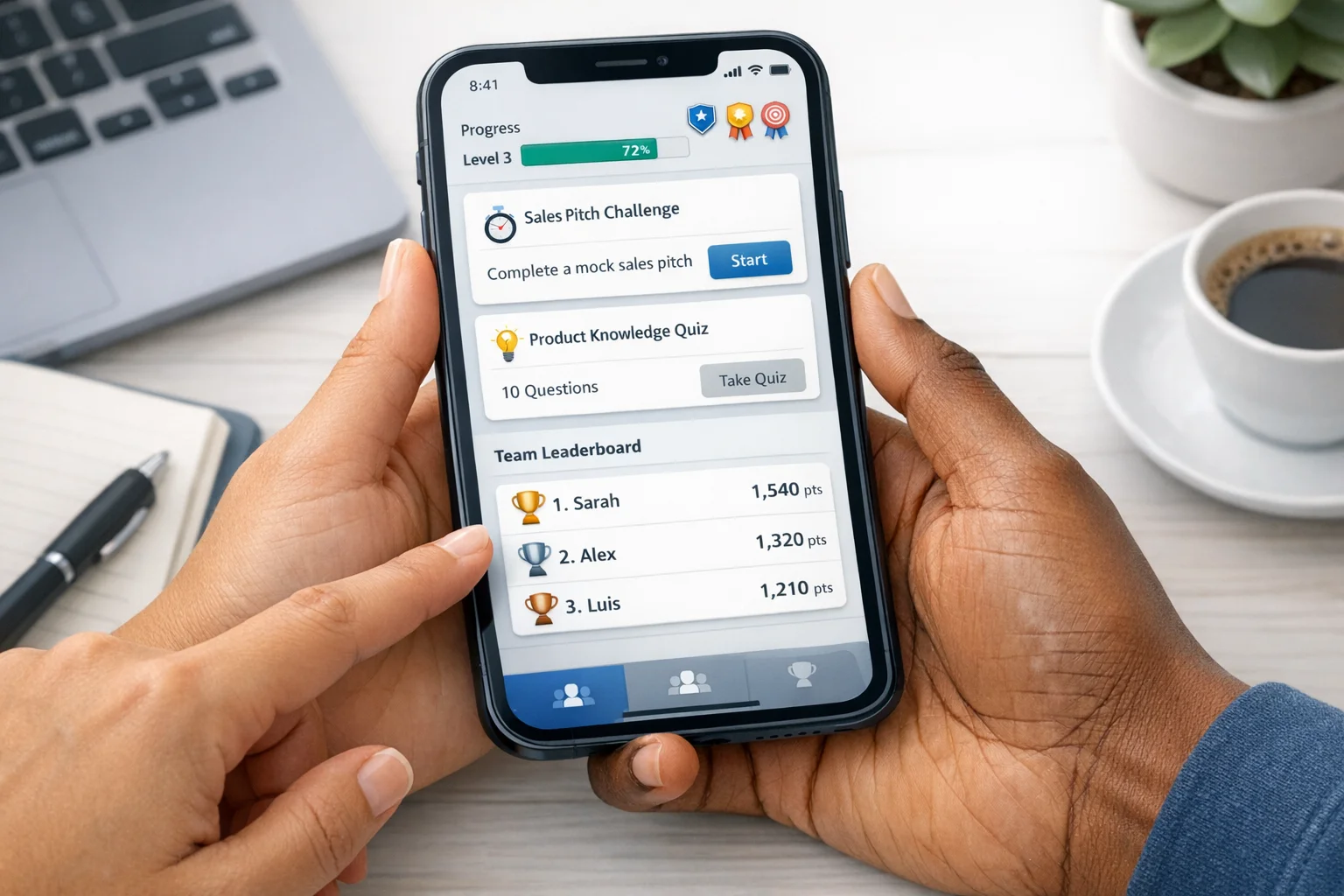
Translating principles into eLearning mechanics that work
Here’s how we typically convert principles into shippable mechanics inside a modern LMS or learning app.
Progress maps over bare percentages. Replace a lonely 47% with a named map of check‑points (e.g., “Brief the stakeholder,” “Run the safe demo,” “Handle an objection”). Learners should always know what’s next and why it matters.
- Tip: Show prerequisites and optional side quests. Choice supports autonomy, visible mastery supports competence.
Elaborated feedback by default. When learners answer, show why a response is right or wrong and how to repair it. Keep it short and actionable; link to a single “see one” example.
- Use answer‑level feedback for misunderstandings that repeat, and hint‑level feedback before final attempts. Shute’s guidelines are a good checklist for clarity and tone (formative feedback review).
Low‑stakes retrieval everywhere. Replace end‑of‑module exams with frequent, single‑concept checks. Randomize variants, allow resets, and make feedback instant. The retrieval literature favors many short pulls over one big lift (retrieval practice review).
Spacing built in. Schedule automatic “lightweight refreshers” 2–3 days, then 10–14 days after core training. Nudge learners back for 60‑second checks rather than 20‑minute reruns. The spacing effect is doing the quiet work here (spacing meta‑analysis).
Challenge ladders that map to real skills. Levels should correspond to competencies (“Can de‑risk the API call,” “Can escalate a data incident”). Unlock higher‑fidelity scenarios as evidence accumulates.
Choice without chaos. Offer two or three equivalent practice paths that converge on the same objective. Autonomy rises without fragmenting content.
Social proof minus humiliation. Swap monolithic leaderboards for opt‑in, small cohort ladders or progress bands (“Not started, In motion, Demonstrating, Teaching”). Recognize improvement deltas, not just absolute rank.
Meaningful badges. Tie badges to performance behaviors (“Handled three red‑team phish correctly across two weeks”) and set them to expire, which encourages healthy refresh.
Leaderboards, badges, and streaks without the side effects
These tools aren’t bad; they’re often misused. A few guardrails:
Leaderboards:
- Use relative progress within small cohorts. Hide exact ranks outside the top few. Show “You advanced 3 spots this week” rather than “You’re 127th of 483.”
- Offer opt‑out and private mode. Public comparison can harm novices or marginalized groups. The meta‑analytic picture is mixed; context and design matter (Frontiers meta‑analysis).
Badges:
- Make the criteria transparent and skill‑tied. Display the behavior behind the badge.
- Avoid “attendance” badges. Reward corrective action and application, not clock time.
Streaks:
- Cap daily streak influence. Favor scheduled reviews at pedagogically useful intervals over calendar‑day pressure. Spacing beats streaking for memory (spacing meta‑analysis).
Examples you can ship this month
If you’re enhancing a module inside your LMS, start with retrieval, feedback, and spacing. If you’re pairing your module with an app‑based layer for live reinforcement, mix in quick, real‑world missions.
- [Multiple Choice | 20 pts]: Which subject line screams phishing louder than caps lock?
- [Q&A | 30 pts]: In 12 words, define “least privilege” without using the word “access.”
- [Photo | 40 pts]: Spot three physical‑security misses in your workspace, capture discreetly.
- [Video | 60 pts]: Show a 20‑second clean PPE check before entering the lab.
- [QR Code | 50 pts]: Find the code hidden in our conduct guide’s gray call‑out box.
Keep the writing intriguing and short. Reward the behavior you want repeated. Make feedback the star.
Building your measurement plan before you build features
Track these leading indicators as you pilot:
- Retrieval attempts per learner per week and the proportion completed with elaborated feedback viewed.
- Spacing adherence: percent of learners completing at least one scheduled review at each interval.
- Time‑to‑repair: how long it takes a learner to convert a common miss into a correct attempt after reading feedback.
- Scenario transfer rate: percent of learners who solve a novel scenario without hints.
Then connect to lagging indicators: - On‑the‑job application: checklist completion in real workflows, peer confirmations. - Error rates: incident categories the training targeted. - Time to competence: manager‑recorded independence on target tasks.
If a feature doesn’t move one of these lines after a fair test window, change it or cut it.
A 60–90 day rollout blueprint
Week 0–2: Define outcomes and design guardrails - Translate learning objectives into observable behaviors and metrics. - Pick two target mechanics (e.g., retrieval + feedback; or progress map + challenge ladder). Keep the pilot tight.
Week 3–4: Prototype and instrument - Build a micro‑journey: 15–25 minutes of content + 6–10 retrieval checks with elaborated feedback. - Configure spaced reviews. Wire event tracking for attempts, feedback views, and review completions.
Week 5–6: Pilot with a real cohort - Recruit 30–60 learners from the actual audience. Offer opt‑in privacy on comparisons. - Run light usability tests on the feedback experience. Clarity wins over cuteness.
Week 7–8: Analyze and adjust - Compare retrieval attempts and spacing adherence to a recent non‑gamified module. - Tune item difficulty and feedback length. Prune badges that reward seat time.
Week 9–12: Expand and harden - Add a second scenario tier gated by demonstrated competence. - Promote within teams; introduce small cohort progress bands instead of a global board.
Common mistakes we keep seeing (and how to avoid them)
- Points for presence. Rewarding logins teaches logging in. Tie points to practice and repair.
- Wall‑of‑text feedback. Learners skip it. Cap at a few clear sentences, link to a single example, then re‑ask.
- Global leaderboards. They skew to experts and demotivate beginners. Use cohorts and improvement deltas.
- Streak obsession. Streaks punish vacations and sick days. Schedule spaced reviews; don’t make people feel bad for pausing.
- No instrumentation. If you can’t see attempts, feedback views, and reviews, you’re flying blind.
- Cognitive glitter. Extra animations and sounds tax attention. Spend polish on clarity and responsiveness.
Where Scavify naturally fits
When training needs to jump the screen and show up in daily behavior, layering app‑based challenges on top of your module works. Scavify lets teams pair varied challenge types with automation and browser + app flexibility, so the same program can deliver quick retrieval checks in the LMS and real‑world missions after. That mix keeps practice active without bloating the course.
FAQs
What is eLearning gamification in practical terms?
It’s the use of progress, feedback, and calibrated challenge to make practice clearer and more effective. Points, badges, and leaderboards are optional tools, not the point. The design goal is better retention and transfer, not just higher click counts.
Does gamification really improve learning outcomes?
Research syntheses suggest it can, when aligned with pedagogy and context. See the meta‑analyses in Educational Psychology Review and Frontiers in Psychology for effect patterns by element and setting (gamification meta‑analysis, 2020; Frontiers meta‑analysis, 2023).
What should I add first if I only have time for one change?
Add frequent, low‑stakes retrieval with short, specific feedback, then schedule spaced refreshers. The retrieval and spacing evidence is strong and usually delivers fast, measurable gains (retrieval practice review, 2021; spacing meta‑analysis).
How do I prevent leaderboards from demotivating people?
Make them opt‑in, cohort‑based, and focused on improvement over raw rank. Recognize upward movement and personal bests. Avoid public shaming of low ranks and allow private mode.
How do I write feedback that helps without overwhelming?
Keep it brief, specific, and instructional: why the answer is right or wrong and what to try next. Link to exactly one example. Shute’s review summarizes effective patterns for tone and timing (formative feedback review).
Are streaks good for learning?
They can encourage return visits, but daily streaks often punish breaks and encourage shallow interactions. Favor scheduled reviews at pedagogically useful intervals. Spacing beats streaking for long‑term memory (spacing meta‑analysis).
How do I prove this is working?
Instrument from day one. Track attempts, feedback views, scheduled reviews completed, and performance on new scenarios. Pair that with on‑the‑job indicators like error reduction or time to competence. If a mechanic doesn’t move a metric, adjust or remove it.
Where do I start if my LMS is limited?
You can still ship retrieval checks with elaborated feedback and schedule spaced follow‑ups by email or app notifications. For real‑world reinforcement, pair the module with lightweight app‑based challenges that feed data back to your dashboard.
Get Started with Gamification
Scavify is the world's most interactive and trusted gamification app and platform. Contact us today for a demo, free trial, and pricing.
YOU MAY ALSO LIKE